
Back in May, I started to notice that some of the requests on a project of mine had gradually gotten slower and slower in the past few months. While the app itself was relatively snappy, it got to a point where in production, simple page loads were taking 4-8 seconds to display just a few tiles of data. As this was a gradual problem, I suspected the issue dealt with the queries into large tables (2M+ records). I copied my prod database back into my local environment to debug:
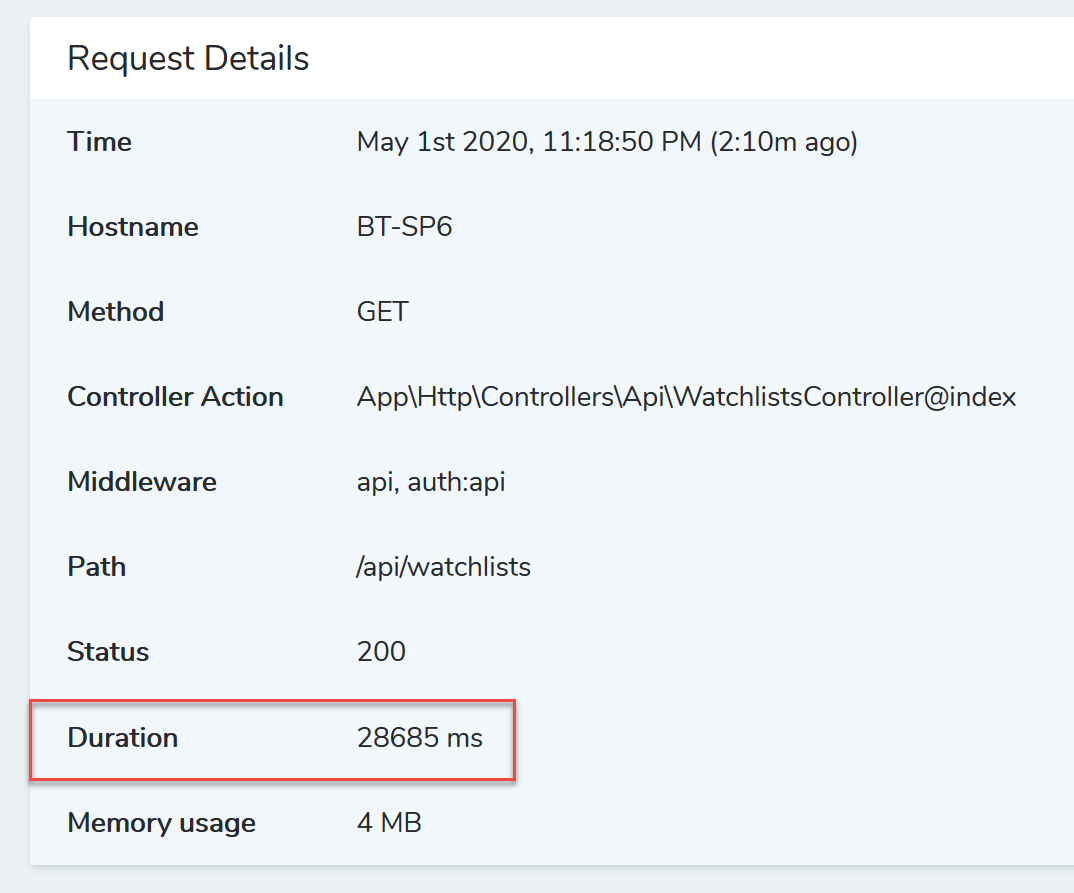
28 seconds! Whew. We've got a ways to look. Let's dissect the queries involved in this endpoint:
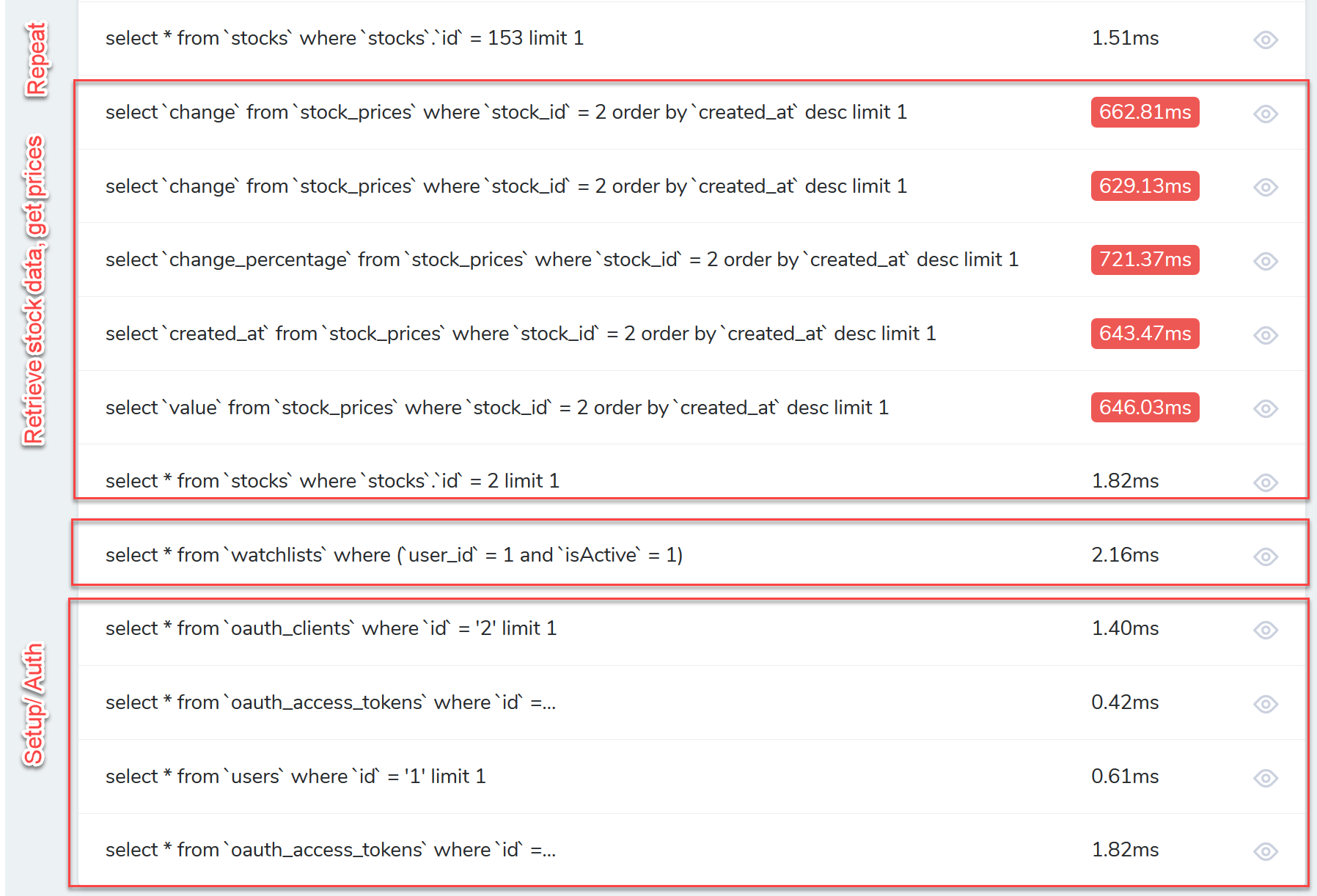
I broke it up in to a few sections here. First is setup/ auth, which is handled through Laravel Passport. The next line retrieves each of the watchlist records. Think of watchlists as the custom pivot table in a many-to-many relationship between users and stocks.
The next section, with a number of long running queries is an example of poorly using a forEach loop to fetch the stock/ stock prices associated with a watchlist record. You can see here I'm fetching the stock itself, then a number of attributes from the stock_price table. This is far from ideal.
Eager Loading
Let's fix the N+1 problem associated with the repeated nature of each stock price query above. In Laravel, we can eager load relationships using ->with().
public function index(Request $request)
{
$user = $request->user();
$watchlists = Watchlist::where([
[ 'user_id', '=', $user->id], // match based on user
[ 'isActive', '=', 1 ] // make sure sprint is active
])->get();
}public function index(Request $request)
{
$user = $request->user();
$watchlists = $user->watchlist_stocks;
return new WatchlistResource($watchlists);
}
watchlist down to the user model, then we'll build up what we need for the API from WatchlistResourceUser model:
class User...
public function watchlist_stocks()
{
$watchlist = $this->belongsToMany(Stock::class,'watchlists') // watchlist is a custom pivot name
->withPivot('date_added','date_removed','isActive'); // get extra columns from the watchlist table
return $watchlist->wherePivot('isActive', 1) // only return stocks actively on watchlist
->with('latest_price');
}Great, so we've made progress here. We're no longer querying for stock prices (latest_price is a hasOne relationship for the most recent stock_price), and we're passing all the needed data to the resource at once.
Here's the actual query that gets generated to fetch those stock prices:
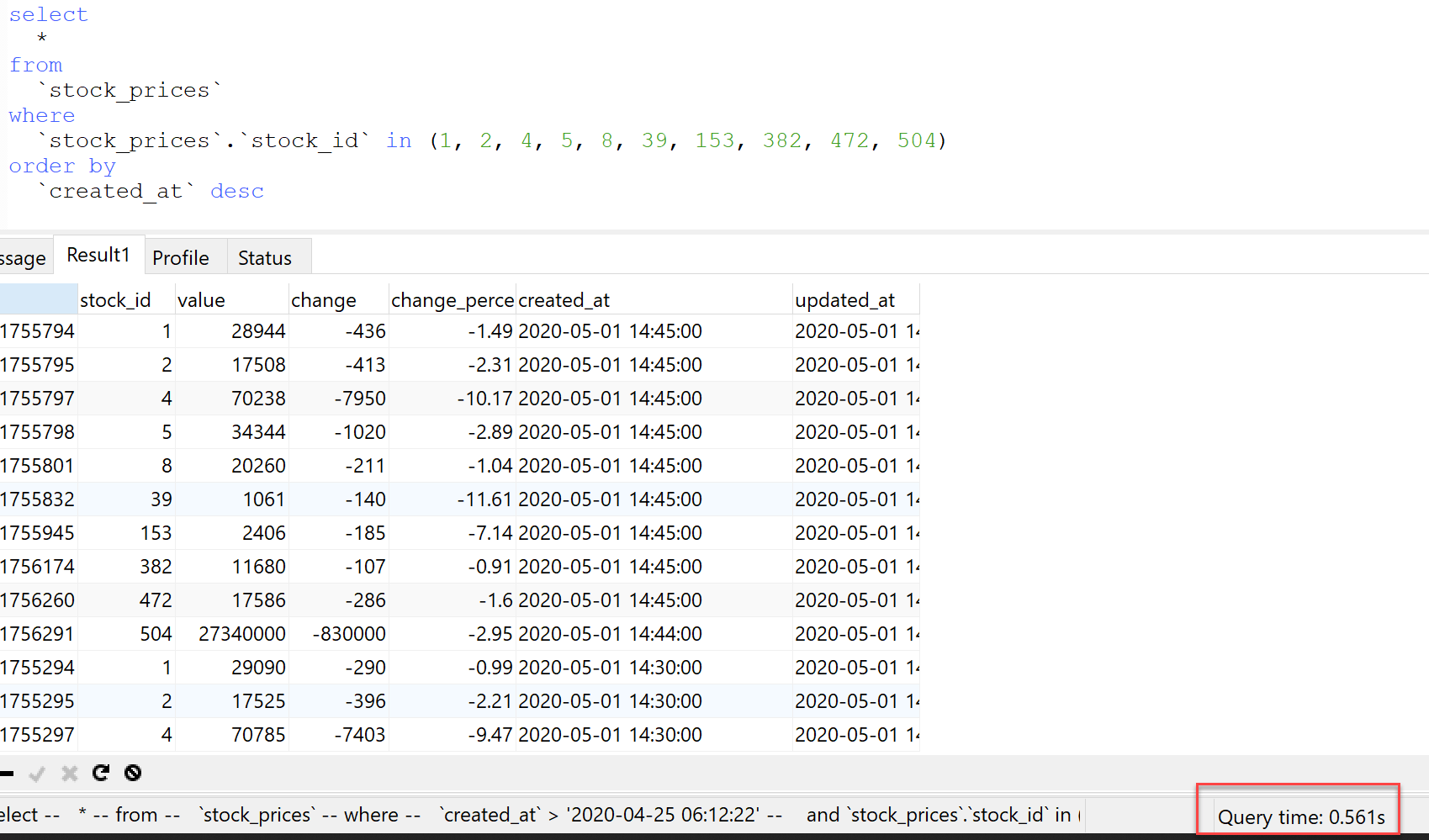
->with('latest_price') query takes about half a second... Hmm.You'll see we've solved the first problem with the in clause allowing us to return prices for multiple stocks. The flaw here? We haven't limited any results, so the database engine is having to traverse quite a few rows. Running explain on the query shows it's still having to access 50k+ rows at any given time, even with the foreign key index already in place.
Introduce a LIMIT
So it turns out the Eloquent, the ORM for Laravel, is already pretty capable with the way it generates queries. For example, whenever you access a hasOne relationship, the query will always end with limit 1. Probably basic, but I thought that was nifty. As you might imagine, when you're querying a large table, this has tremendous benefits as it materially reduces the number of rows that need to be touched as a part of the query. Below I'll walk through the two tries it took me to get the right syntax to correctly limit the query above.
First, if I'm returning n number of stocks, then I only need n number of stock prices, as the method will return the latest stock price. Laravel has a handy method on eloquent called count(), that simply counts the number of records in a collection/ eloquent query. So if my $watchlist returns 10, then I can limit my query for stock prices to 10. Easy as:
$limit = $watchlist->count(); // count the number of stocks that got returnedQuick caveat to the above: since we're limiting the number of records returned, it is very important that stock_prices in this instance are always in sequence of one another. So if I have 500 stocks in a database, then stock_price.id 0 - 499 should map to all 500 stocks.
Here's an example of a bad scenario:
| id | stock_id | value | change | created_at |
|---|---|---|---|---|
| 5000 | 1 | 50 | 0.5 | 5/5/2020 17:00 |
| 5001 | 1 | 51 | 1 | 5/5/2020 17:01 |
| 6001 | 2 | 25 | 2.2 | 5/5/2020 17:00 |
| 6002 | 3 | 35 | 3.2 | 5/5/2020 17:00 |
| 6003 | 4 | 10 | 1.3 | 5/5/2020 17:00 |
If the query above was looking to pull prices for stocks 1,2,3,4, then the SQL would end with limit 4. When this table is queried, it will start with id 5000, then 5001, 6001, and 6002 before returning. This is a problem because we've returned two prices for stock_id 1 and none for stock_id 4.
Ideally speaking, we would only populate the stock_prices table in a predictable fashion such that this doesn't happen. With that being said, there are scenarios where it could happen, so we'll have to build in a little error handling in our final version.
Limit Try 1
Here's my first attempt:
class User...
public function watchlist_stocks()
{
$watchlist = $this->belongsToMany(Stock::class,'watchlists')
->withPivot('date_added','date_removed','isActive');
$limit = $watchlist->count(); // count the number of stocks that got returned
return $watchlist->wherePivot('isActive', 1)
->with('latest_price')
->limit($limit);
}The flaw here, discovered through trial and error, is that the ->limit that I've added, is being appended to the watchlist query, not the query that fetches latest_price. Here's a visual from Laravel Telescope:
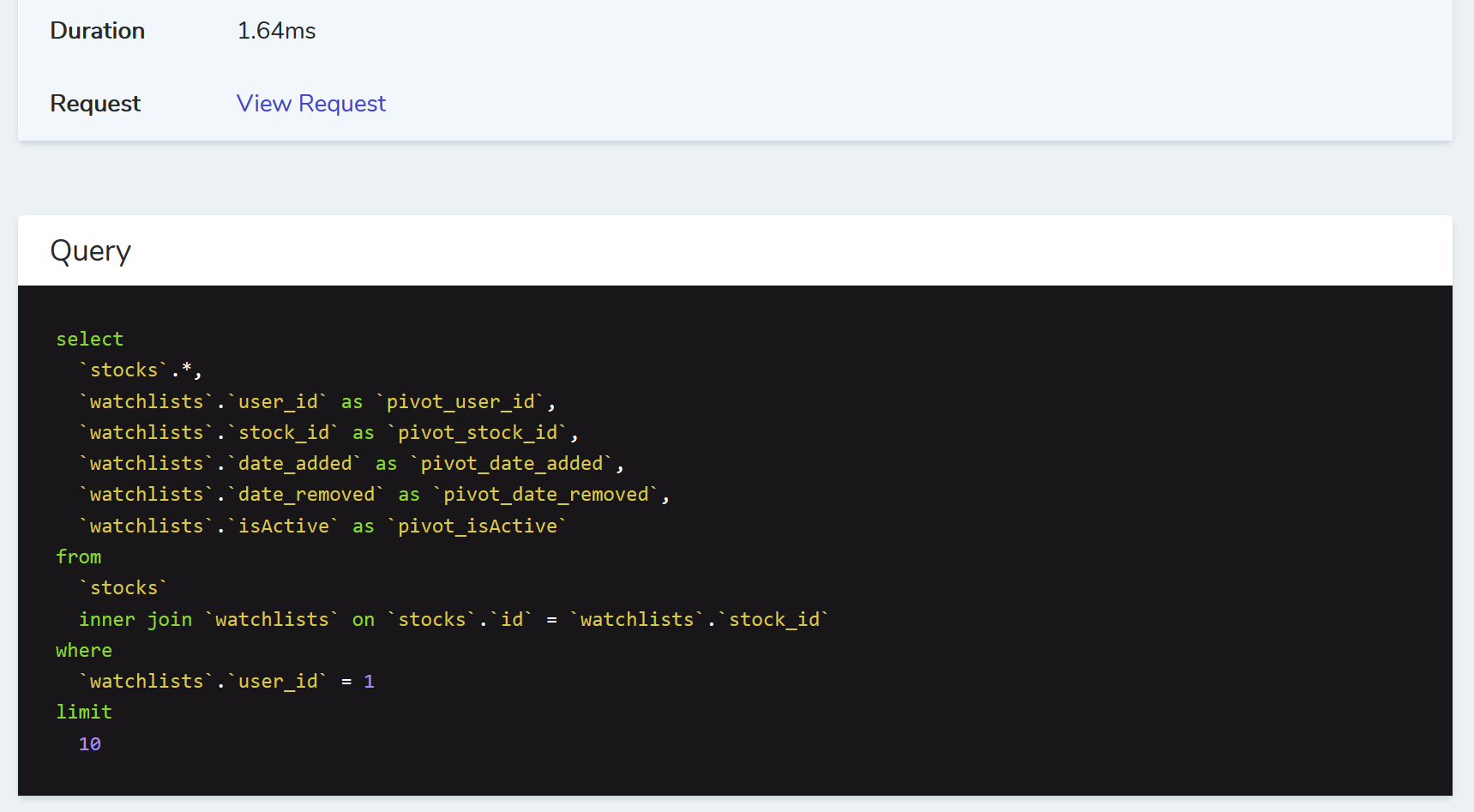
limit got added here? This doesn't really add much value.As mentioned, this limit 10 doesn't help me. Since a user likely has between 0-20 stocks on their watchlist, this means the entire watchlist table is a few thousand records, max. Of course, this is proportional to the number of users, but that's not a problem I have. Let's see if we can move the query into the eager load.
Limit Try 2:
Learning from my mistakes, I need to use a callback in the ->with rather than directly calling ->limit on the $watchlist record.
class User...
public function watchlist_stocks()
{
$watchlist = $this->belongsToMany(Stock::class,'watchlists')
->withPivot('date_added','date_removed','isActive');
$limit = $watchlist->count();
return $watchlist->wherePivot('isActive', 1)
->with(['latest_price' => function ($query) use ($limit) {
$query->limit($limit); // limit stock price results to number of stocks we have total
}]);
}This in turn produces a query like this one:
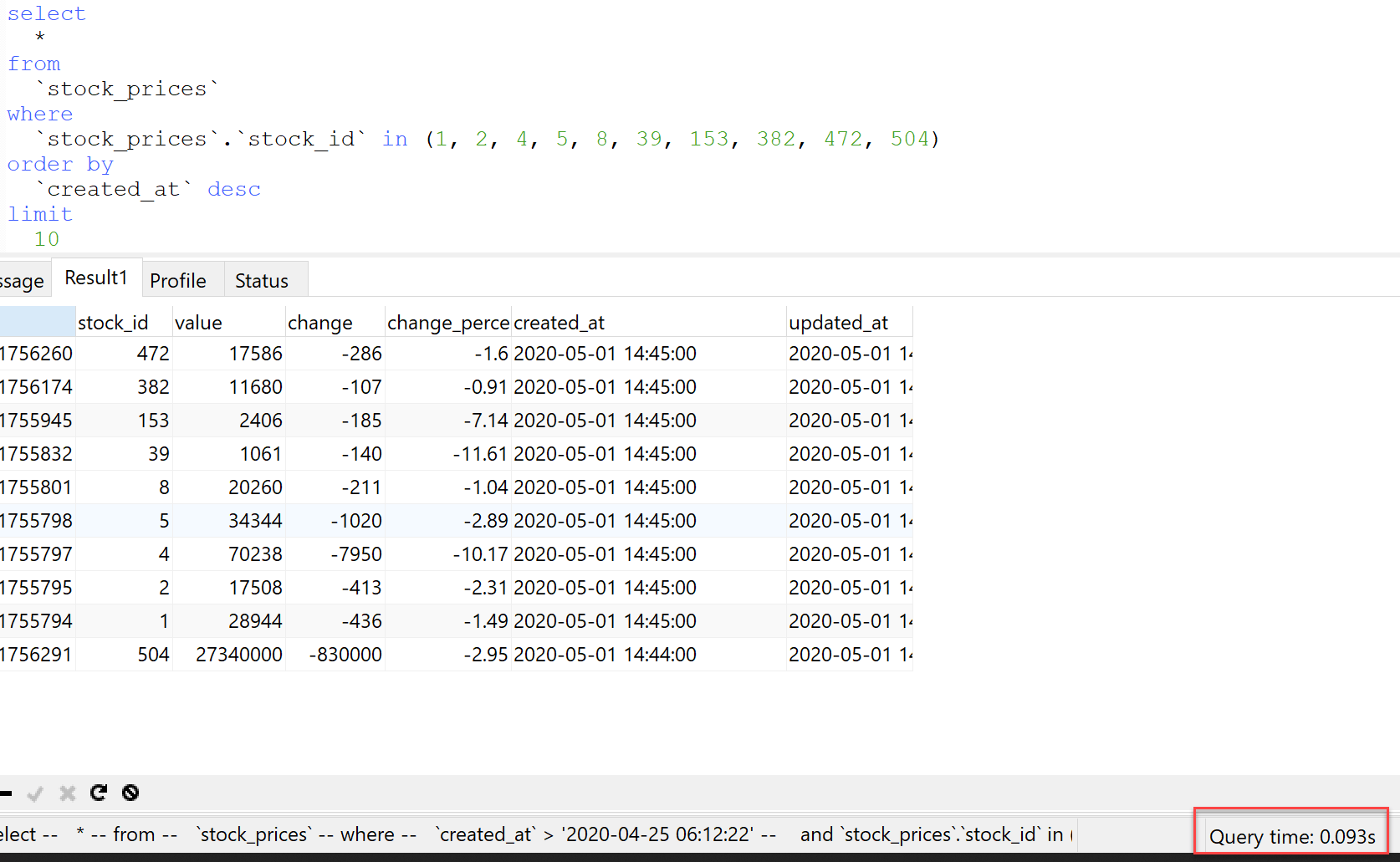
Notice how adding that limit moved our query from about half a second to less than a tenth of a second? That's a material improvement, and pushes us back to sub-second page load times.
Error Handling
I explained above how this approach assumes that you would never have multiple stock_prices that belong to a single stock, in a row. If that were the case, the limit would cause it to return multiple records for one stock, and subsequently miss stock prices for the "extra" stocks. The query itself will look normal, but in this case, Laravel will fail when it attempts to access a price that wasn't actually retrieved. Not wanting to sacrifice my fast query in a majority of scenarios, I added a "check" that effectively verifies all data was returned as expected. If not, it reruns the query but with an arbitrarily high limit, rather than the exact figure. I will not claim this is the best method - but it works for me, and only happens very rarely.
Firstly, I added an argument to my watchlist_stocks() method on the User model for an $unlimitedQuery as a boolean, defaulting to false. The thought process being that when this method is accessed normally, the method will behave exactly as it does previously, relying on count() to get the limit figure. However, if the method is called as watchlist_stocks(TRUE), then the $limit is arbitrarily set to 10000000. This is far from the theoretical max of SQL limits, but I figure it's more than enough headroom to skip over any instances of out-of-sequence stock prices. Resulting method looks like this:
class User...
public function watchlist_stocks($unlimitedQuery = false)
{
$watchlist = $this->belongsToMany(Stock::class,'watchlists')
->withPivot('date_added','date_removed','isActive');
if($unlimitedQuery) {
$limit = 1000000; // set limit arbitrarily high so all prices are returned
} else {
$limit = $watchlist->count(); // count the number of stocks that got returned
}
return $watchlist->wherePivot('isActive', 1) // only return stocks actively on watchlist
->with(['latest_price' => function ($query) use ($limit) {
$query->limit($limit);
}]);
}
Back on my controller, I now need to "check" after the query is ran for the first time if all data is present. I can do this by utilizing the every method, that will loop through each record returned and attempt to find the latest_price attribute. I then flip the equality so that the variable $dataMissingFromQuery will be TRUE if any stock is missing latest_price. In that scenario, I simply rerun the query with the $unlimitedQuery as TRUE and pass the new collection to the resource. This does add ~.5 seconds of time to a page load, but it's rare, gets logged for me, and really is way better than 30 second page loads:
class WatchlistsController...
public function index(Request $request)
{
$user = $request->user();
$watchlists = $user->watchlist_stocks()->get();
// this test will return TRUE if latest_price does not exist on the stock
$dataMissingFromQuery = !$watchlists->every(function ($stock) {
return $stock->latest_price;
});
if($dataMissingFromQuery) {
// log the bad query
Log::alert("Query missing data due to LIMIT: watchlistsController@index"
. PHP_EOL . "Stocks involved: " . $watchlists->pluck('symbol')
);
// pass "TRUE" to argument in order to force LIMIT to be very high
$watchlists = $user->watchlist_stocks(TRUE)->get();
}
return new WatchlistResource($watchlists);
}
So what's the lesson to be learned here? If I had to boil it down:
- Be conscious of the N+1 problem
- Be careful utilizing database queries in a
forEachloop - Hypothesize the realistic size of tables in production while testing
- Use appropriate logging to help spot deficiencies in your code
Last thing - if you're curious what app I'm referencing in this post - it's Carbon. Carbon is a (currently) paper trading platform that simulates realistic risk-conscious investment strategies utilizing market derivatives to control investment risk - all behind the scenes and exceptionally seamless. The app itself is a Vue SPA with a Laravel backend, so I'm always working to make the experience better. This post is an example as such. Thanks for reading.

Member discussion: